AI가 응급 상황을 인지하는 방법

알체라
2023년 7월 27일 (목)
2023년 7월 27일 (목)
행동인식 AI를 통해 예방할 수 있는 사고 종류
Table of Contents
- 머신 러닝의 3가지 유형을 통한 학습
- 딥러닝을 통한 효율성 증대
알체라의 핵심 영상인식 AI (Visual AI)인 SMART VIEWING은 얼굴인식, 행동인식, 이상상황 감지로 구분됩니다. 그 중, 행동인식 AI (Behavior Analysis)는 영상 속 객체(Object)의 고유 움직임과 사물정보 등을 정확히 파악하여 상황을 분석하는 기술로, 24시간 보호가 필요한 노약자 및 환자를 모니터링하여 효율적인 안전관리를 가능하게 합니다.
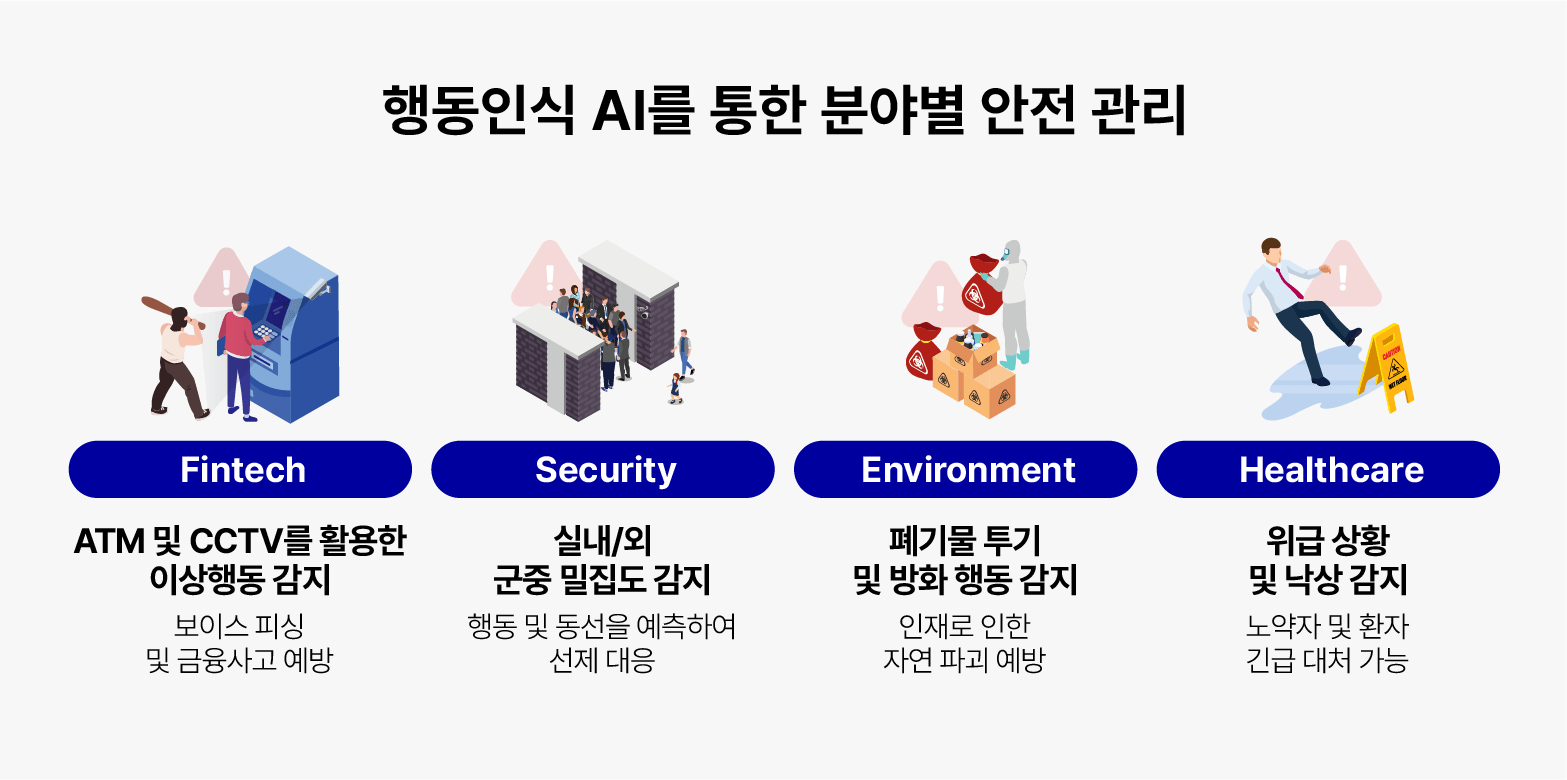
질병관리청에 따르면, 작년 응급실을 내원하는 65세 이상 환자 중 추락 및 낙상 환자는 57.7%로 연령층 중 가장 높습니다. 70세 이상 노인 1만 명 중 2.6명은 추락/낙상으로 사망한 것으로 보고됩니다. 또한 미국 정부의 건강 보호 기관인 CDC(Centers for Disease Control and Prevention)에서 보고된 2017년 연구에 따르면, 1999년부터 2007년까지 9년 동안 미국 65세 이상 노인 중 낙상으로 인한 사망이 55% 증가한 것으로 집계되며, 2030년에는 1시간에 7명의 노인이 낙상으로 사망할 것으로 예측했습니다.
낙상은 전 연령층에서 발생하나, 노화에 따른 신체기능의 제한이 노년층의 낙상을 일상 곳곳에서 빈번히 일어나게 하는 이유입니다. 또한 고령층의 낙상은 골절 및 골절 합병증으로 이어지기 쉬워, 사전 예방 및 빠른 초기대응이으로 빠른 골든 타임으로 확보하는 것이 중요합니다.

AI가 위급 환자를 알아보는 방법
행동인식 AI는 영상 속 사람을 찾아 행동을 분석하고 동선을 파악합니다. 사람의 위치와 영역을 탐지하여 신체 정보 및 이동 정보를 파악하고, 시간의 흐름에 따라 자세의 변화나 최종 행동을 분류하게 됩니다. 크게 3단계로 구성된 과정을 통해 행동인식 AI는 영상 속에서 위급 환자를 인식하고 추적하는 데 필요한 정보를 추출하며, 이를 통해 환자의 건강 관리와 응급 상황 대응에 도움을 줄 수 있습니다.
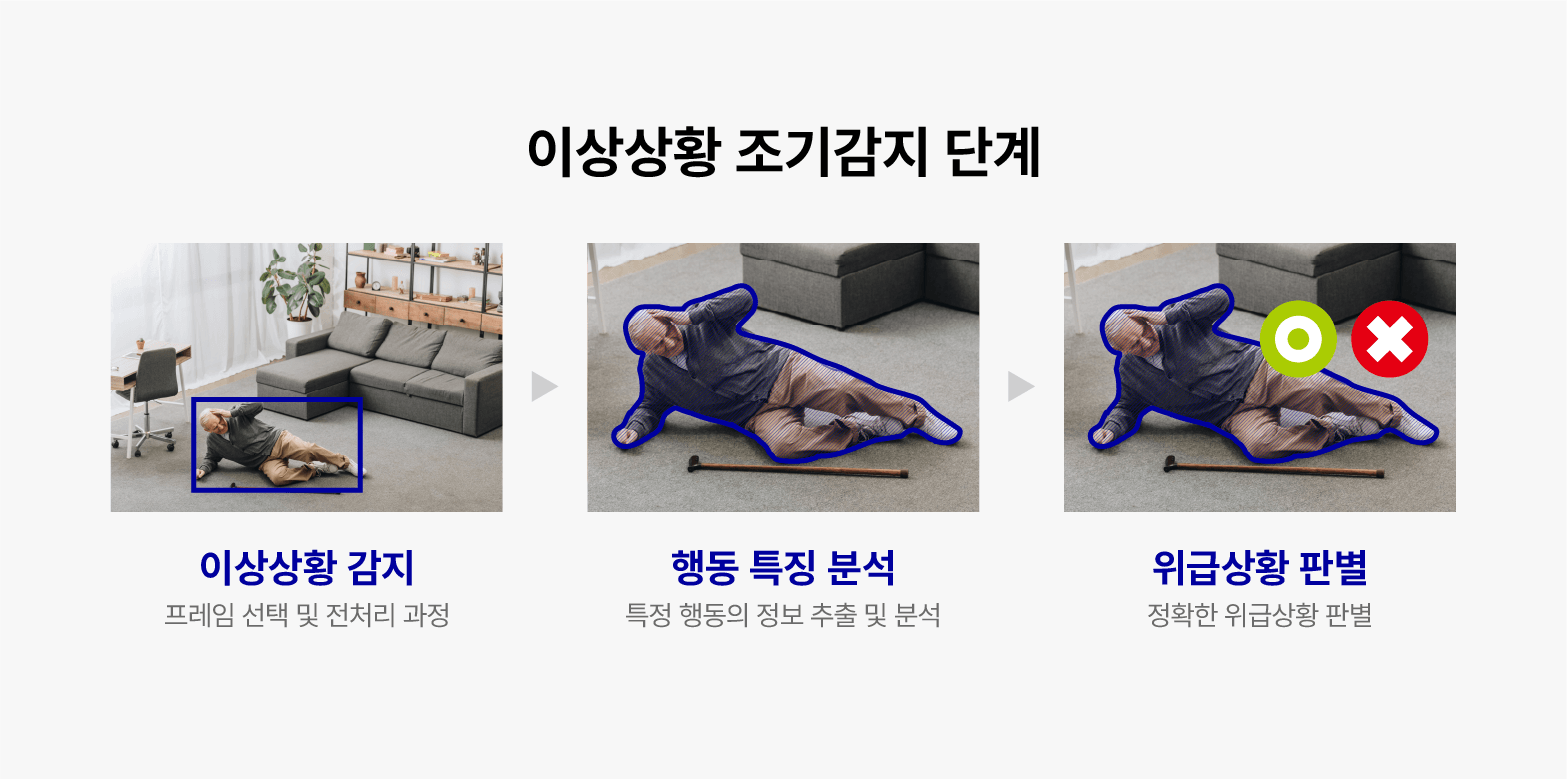
첫 번째 단계는 ‘이상상황 감지’로 영상 데이터로부터 적절한 프레임을 선택, 전처리 과정을 거치게 됩니다. 영상 데이터의 다수의 프레임 중, 핵심 정보를 담고 있는 프레임을 선택, 분석합니다. 해당 프레임의 해상도 및 이미지 크기 조정, 노이즈 제거 등의 전처리 과정이 수행됩니다.
그 다음은 ‘행동 특징 분석’입니다. 전처리된 프레임으로부터 특징을 추출하여 학습된 데이터를 기반으로 감지된 행동 특징이 위급상황인지 분석합니다. 관절 추정 기술을 기반으로 행동의 특징을 파악하여 이상 유무를 판단할 수 있는 정보를 추출합니다.
마지막 ‘위급상황 판별’ 단계에서는 추출된 특징을 기반으로 위급환자를 분류하고, 필요에 따라 객체 추적하여 위급환자인지 아닌지를 정확하게 판별합니다. 객체 추적을 통해 영상 내에서 위치를 이동하며 이상행동을 보일 시 즉각적인 정보를 추출합니다.
AI가 응급 상황을 인지하는 방법
행동인식 AI를 설계할 때는, 머신 러닝과 딥러닝 알고리즘의 장단점을 종합적으로 고려하여 적절히 선택 및 활용하는 것이 중요합니다. 데이터셋의 크기와 특성, 컴퓨팅 자원, 시간 제약 등을 고려하여 학습 방식 및 활용 모델이 달라지기 때문입니다.
머신 러닝의 3가지 유형을 기반으로 행동인식 AI 구현 방법과, 딥러닝 모델을 활용하여 이미지 처리의 효율성을 높이는 방법을 함께 알아보도록 하겠습니다.
1. 머신 러닝의 3가지 유형을 통한 학습

지도 학습 (Supervised Learning)
지도학습은 라벨링된 데이터를 기반으로 모델을 학습하는 방식입니다. 위급환자로 분류되는 행동 데이터를 통해 모델을 훈련, 학습시키고 위급환자 식별 정확도를 높입니다.한 마디로 정답지로 학습하는 방법이라고 할 수 있습니다.
비지도 학습 (Unsupervised Learning)
반대로 비지도 학습은 라벨링되지 않은 데이터를 기반으로 모델을 학습하는 방식으로, 노약자 및 환자들의 다양한 행동 데이터를 통해 모델을 훈련시키고,이상행동의 특성을 추출하는 데 중점을 둡니다. 이렇게 추출된 데이터들을 군집화하여 행동 패턴을 파악할 수 있습니다.
강화 학습 (Reinforcement Learning)
강화 학습은 시뮬레이션을 통한 반복 학습을 통해 성능을 고도화 시킵니다. 특정 환경에서 도출된 결과값을 어떤 보상을 받는지를 학습하고, 보상을 최대화하는 방향으로 시스템을 개선해 나갑니다. 올바른 낙상 현상을 인식할 경우 양수를 주고, 그렇지 않을 경우 0 또는 음수를 주는 방식입니다.
2. 딥러닝을 통한 효율성 증대
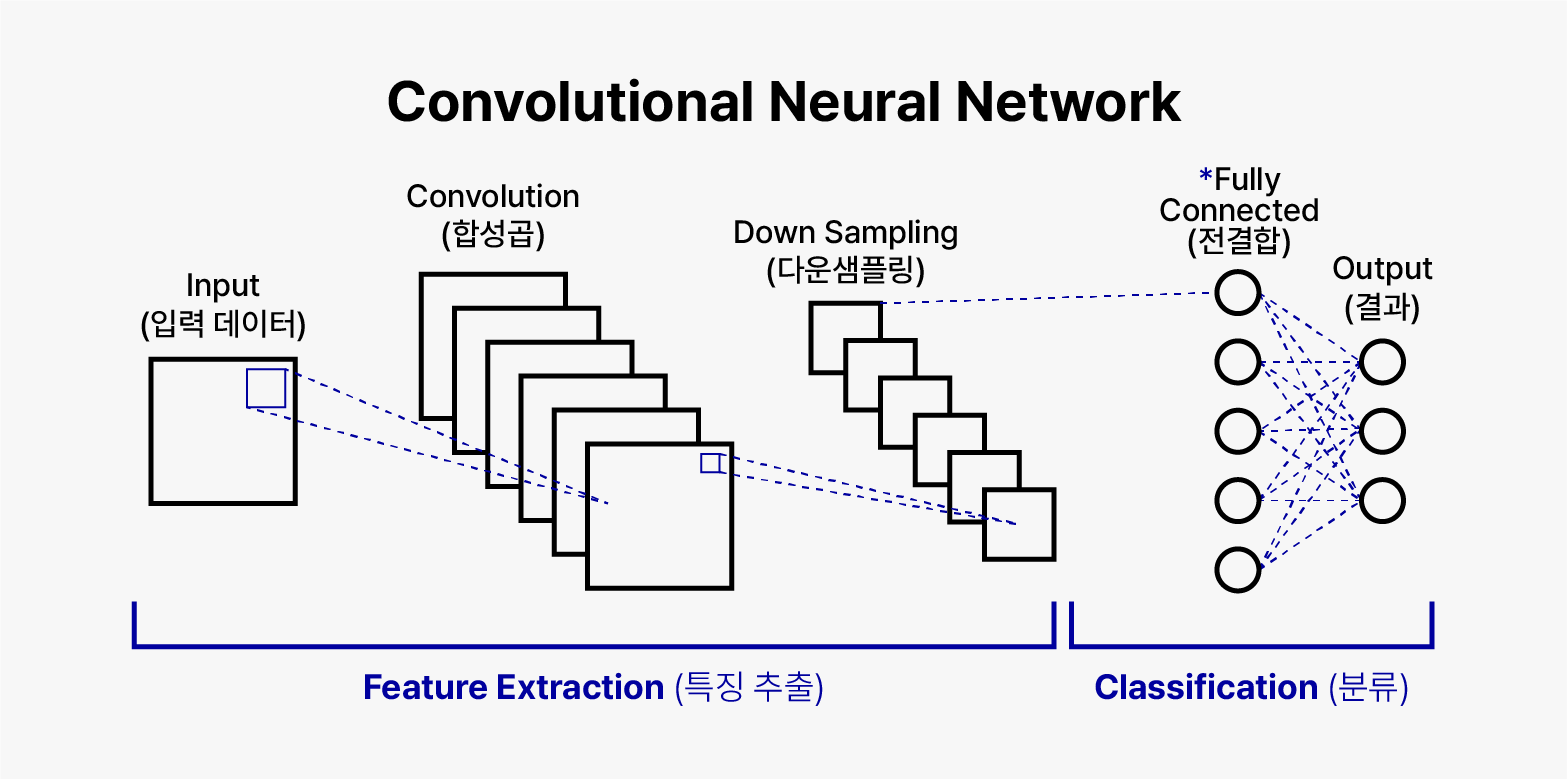
*Fully Connected: 딥러닝 모델에서 데이터를 받아들여 출력을 생성하는 층으로, 분류 작업과 관련되어 활용
CNN(Convolutional Neural Network)는 컴퓨터 비전 분야에서 이미지 인식과 관련된 다양한 작업에 큰 성과를 거두어 온 딥 러닝 모델입니다. 이미지의 공간적인 구조를 잘 파악하기 위해 합성곱 연산 등을 사용하여 이미지에서 특징을 추출하며, 이를 통해 영상 속 객체의 형태, 경계, 텍스처 등 주요한 시각적 특징들을 자동으로 학습할 수 있습니다.
또한, 합성곱과 다운 샘플링 연산을 통해 이미지 내의 특징을 감지할 때, 해당 특징들이 이미지의 어느 위치에 있더라도 잘 인식할 수 있도록 공간적 위치 불변성을 제공합니다. 이로 인해 행동인식 AI는 사람의 위치가 바뀌더라도 안정적인 인식이 가능합니다 .
CNN를 활용한 고성능 산불 조기감지 AI 솔루션 알아보기
[Article] AI를 활용한 산불 대응: 예방과 초동대응의 해결책
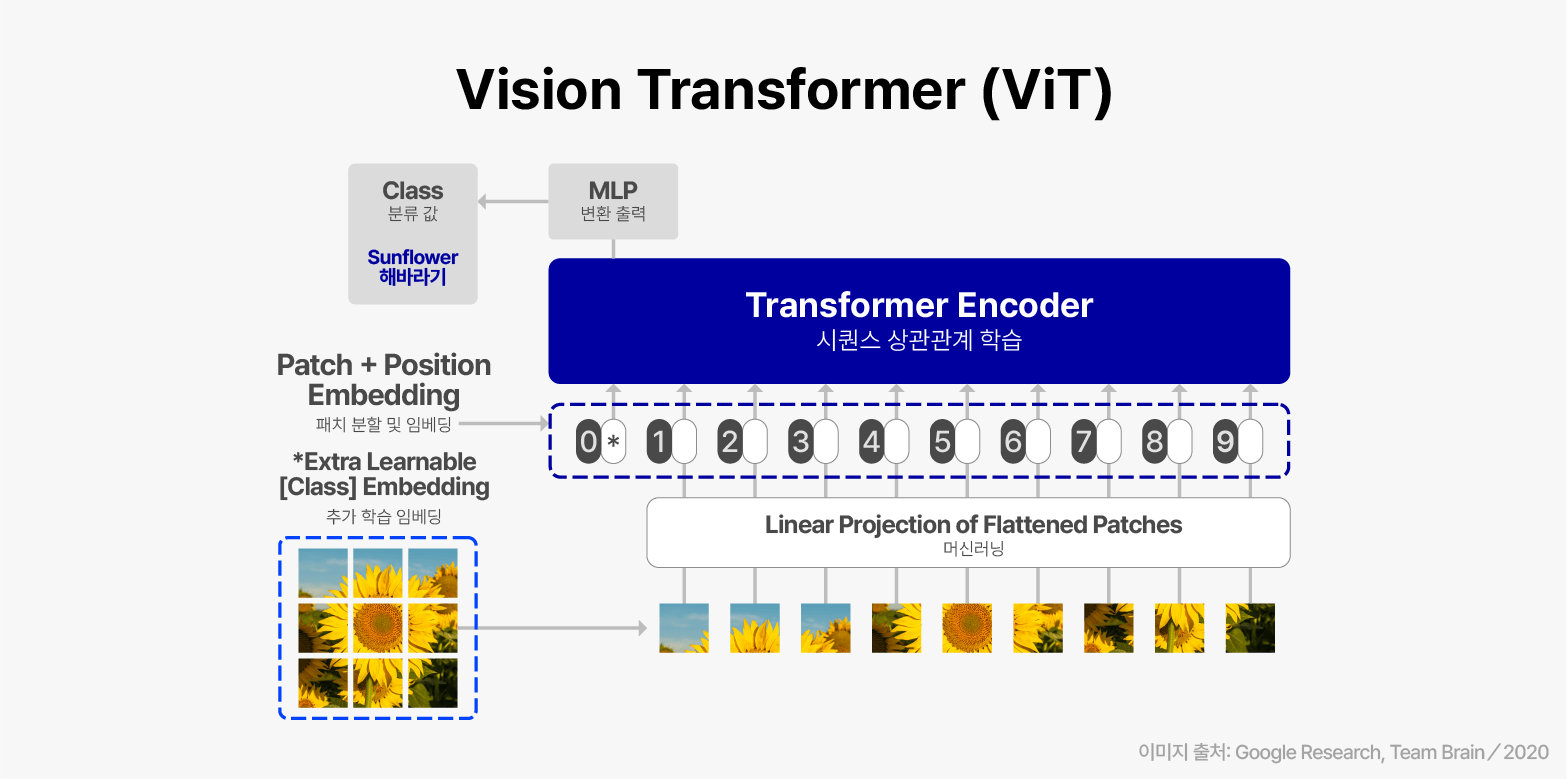
ViT(Vison Transformer)는 자연어 처리 분야에서 활용되던 Transformer 아킥테처를 이미지 분류 작업에 적용한 비전 인식 모델입니다. 이미지를 작은 패치로 분할, 이를 벡터로 변환하여 자연어 처리 기반의 인코더에 입력 후 이미지 특징을 추출하게 하는 방식으로, 대규모 이미지 처리 작업에서 효과적으로 쓰이는 방식입니다.
- Patch + Position Embedding
준비된 입력 이미지를 작은 패치(Patch)로 나누어 위치정보와 함께 임베딩(Embedding) 하는 과정입니다. 이미지를 작은 패치로 분할하는 것은 이미지를 효율적으로 처리하고, 위치정보를 파악하여 모델이 이미지의 전역적인 정보를 파악할 수 있도록 도와줍니다. - Transformer Encoder
패치 벡터(Patch Vector)들은 여러 층으로 구성된 Transformer Encoder에 입력됩니다. 각 층은 *어텐션 메커니즘(Attention Mechanism)과 *피드포워드 신경망(Feed forward Neural Network)으로 구성되어 있습니다. 어텐션은 각 패치 벡터들의 상호 의존성을 학습하고, 피드포워드 신경망은 각 패치 벡터의 특성을 변환하는 데 사용됩니다. - 사전 훈련 또는 미세 조정
ViT는 사전 훈련(Pretraining)과 미세 조정(Fine-Tuning) 단계를 거쳐 성능을 향상시킵니다. 사전 훈련 단계에서는 대규모 이미지 데이터셋으로 모델을 사전 훈련시키고, 이후 원하는 이미지 처리 작업에 맞게 미세 조정을 수행합니다. - 출력 생성
사전 훈련과 미세 조정을 거친 ViT 모델은 입력 이미지를 기반으로 해당 작업에 대한 결과를 출력합니다. 예를 들어, 객체 감지 작업의 경우 감지된 객체의 위치와 결과값 정보를 출력합니다.
ViT는 전역적인 정보 이용과 패치 기반 접근을 통해 이미지 처리에서 높은 성능을 보이는 반면, CNN은 이미지의 지역적인 특징을 강조하는데 특화된 있습니다. 상황과 활용 기능에 따라 두 아키텍처를 적절하게 선택하여 사용하는 것이 중요합니다.
*어텐션 매커니즘: 시퀀스 데이터에서 중요한 정보를 집중하고 상호작용을 고려하는 기술
*피드포워드 신경망: 단방향으로 입력에서 출력으로 전달되는 기본적인 딥러닝 구조
행동인식 AI 고도화를 통한 헬스케어 분야의 혁신
1인 가구 일반화와 고령화된 사회 변화에 따라, 행동인식 AI가 헬스케어 분야에서 확장될 수 있는 영역은 무한합니다. 행동인식 AI와 딥러닝 기술의 발전으로 우리는 본인, 가족부터 노약자와 환자, 의료 관계자들까지 많은 사람의 일상 안전을 보호할 수 있습니다. 노약자나 환자들의 행동을 모니터링하고 이상상황을 신속하게 감지할 수 있습니다. 쓰러짐이나 급작스러운 움직임 변화 등을 감지하여 응급 상황을 조기에 파악하고 적절한 조치를 취하는 것은 물론, 환자들의 일상적인 행동 패턴을 파악하여 개별적인 의료 서비스를 자동화할 수 있습니다.
특히, 병원이나 시설이 아닌 개인의 생활 공간에서도 고령층의 위험상황을 지속적으로 관찰, 지원할 수 있다는 점은 재가(在家) 홈케어 트렌드와 접목하여 발전 가능합니다. 가족 구성원이나 돌봄 제공자가 환자의 움직임, 식사 및 수면 등을 실시간으로 모니터링하고, 생명이 위험받는 상황에 무엇보다도 빠르게 대응할 수 있는 서비스 구현으로 사회 시스템의 문제점들을 해결할 수 있을 것으로 기대됩니다.
연계 콘텐츠:
[Article] 산재부터 생활 안전까지, 모든 안전을 책임지는 영상관제 AI 솔루션
[Article] SMART VIEWING, 세상 모든 디바이스를 ‘똑똑하게’ 만들다
...
...